3.4. Performance
3.4.1. Measuring performance
The performance of the py-pde package depends on many details and general
statements are thus difficult to make.
However, since the core operators are just-in-time compiled using numba,
many operations of the package proceed at performances close to most compiled
languages.
For instance, a simple Laplace operator applied to fields defined on a Cartesian
grid has performance that is similar to the operators supplied by the popular
OpenCV package.
The following figures illustrate this by showing the duration of evaluating the
Laplacian on grids of increasing number of support points for
two different boundary conditions (lower duration is better):
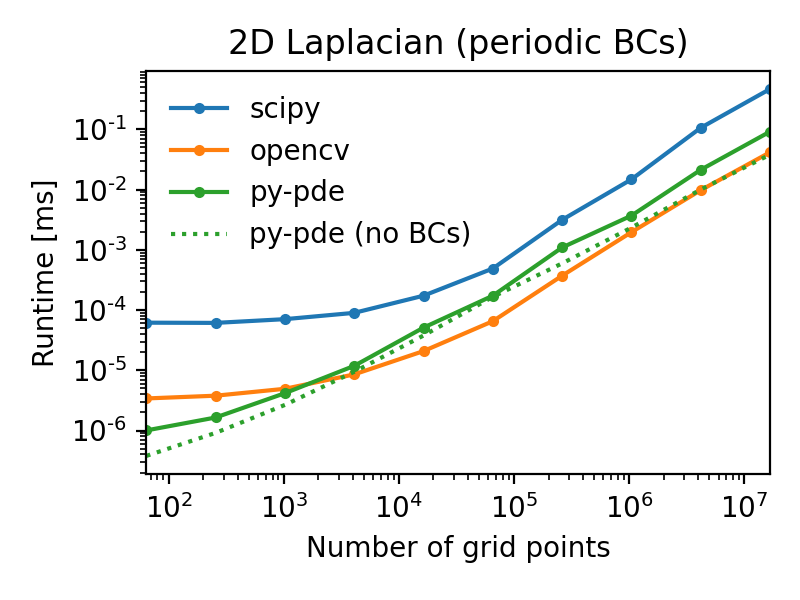
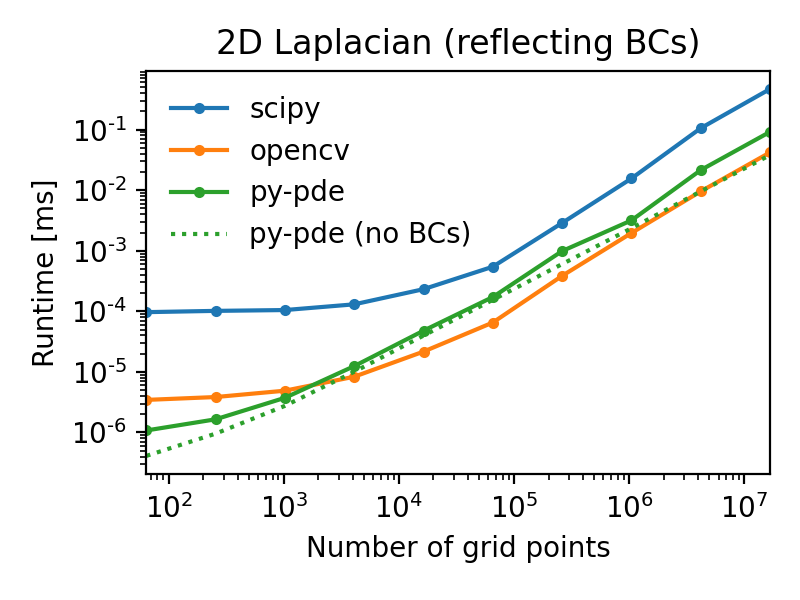
Note that the call overhead is lower in the py-pde package, so that the
performance on small grids is particularly good.
However, realistic use-cases probably need more complicated operations and it is
thus always necessary to profile the respective code.
This can be done using the function
estimate_computation_speed() or the traditional
timeit, profile, or even more sophisticated profilers like
pyinstrument.
3.4.2. Improving performance
Beside the underlying implementation of the operators, a major factor for performance is numerical problem at hand and the methods that are used to solve it. As a rule of thumb, simulations run faster when there are fewer degrees of freedom. In the case of partial differential equations, this often means using a coarser grid with fewer support points. However, there often also is an lower bound to the number of support points if structures of a certain length scales need to be resolved. Reducing the number of support points not only reduces the number of variables to be treated, but it can also allow for larger time steps. This is particularly transparent for the simple diffusion equation, where a von Neumann stability analysis reveals that the maximal time step scales as one over the discretization length squared! Choosing the right time step obviously also affects performance of a simulation. The package supports automatic choice of suitable time steps, using adaptive stepping schemes. To enable those, it’s best to specify an initial time step, like so
eq.solve(t_range=10, dt=1e-3, adaptive=True)
An additional advantage of this choice is that it selects
ExplicitSolver, which is also compiled with numba
for speed.
Alternatively, if only t_range is specified, the generic scipy-solver
ScipySolver, which can be significantly slower.
Additional factors influencing the performance of the package include the compiler used
for numpy, scipy, and of course numba.
Moreover, the BLAS and LAPACK libraries might make a difference.
The package has some basic support for multithreading, which can be accelerated
using the Threading Building Blocks library.
Finally, it can help to install the intel short vector math library (SVML).
However, this is not distributed with macports and might thus be more
difficult to enable.
Using macports, one could for instance install the following variants of typical packages
port install py37-numpy +gcc8+openblas
port install py37-scipy +gcc8+openblas
port install py37-numba +tbb
Note that you can disable the automatic multithreading via Configuration parameters.
3.4.3. Multiprocessing using MPI
The package also supports parallel simulations of PDEs using the Message Passing
Interface (MPI), which
allows combining the power of CPU cores that do not share memory. To use this advanced
simulation technique, a working implementation of MPI needs to be installed on the
computer. Usually, this is done automatically, when the optional package
numba-mpi is installed via pip or conda.
To run simulations in parallel, the special solver
ExplicitMPISolver needs to be used and the entire
script needs to be started using mpiexec.
Taken together, a minimal example reads
from pde import DiffusionPDE, ScalarField, UnitGrid
grid = UnitGrid([64, 64])
state = ScalarField.random_uniform(grid, 0.2, 0.3)
eq = DiffusionPDE(diffusivity=0.1)
result = eq.solve(state, t_range=10, dt=0.1, method="explicit_mpi")
if result is not None: # restrict the output to the main node
result.plot()
Saving this script as multiprocessing.py, we can evoke a parallel simulation using
mpiexec -n 2 python3 multiprocessing.py
Here, the number 2 determines the number of cores that will be used.
Note that macOS might require an additional hint on how to connect the processes even
when they are run on the same machine (e.g., your workstation). It might help to run
mpiexec -n 2 -host localhost:2 python3 multiprocessing.py in this case.
In the example above, two python processes will start in parallel and run independently at first. In particular, both processes will load all packages and create the initial state field as well as the PDE class eq. Once the explicit_mpi solver is evoked, the processes will start communicating. py-pde will split up the full grid into two sub-grids, in this case of shape 32x64, distribute the associated sub-fields to both processes and ask each process to evolve the PDE for their sub-field. Note that boundary conditions are treated and boundary values are exchanged between neighboring sub-grids automatically. To avoid confusion, trackers will only be used on one process and also the result is only returned in one process to avoid problems where multiple process write data simultaneously. Consequently, the example above checked whether result is None (in which case the corresponnding process is a child process) and only resumes analysis when the result is actually present.
The automatic treatment tries to use sensible default values, so typical simulations
work out of the box.
However, in some situations it might be advantageous to adjust these values.
For instance, the decomposition of the grid can be affected by an argument
decomposition, which can be passed to the solve() method
or the ExplicitMPISolver.
The argument should be a list with one integer for each axis in the grid, which
specifies how often the particular axis is divided.
Warning
The automatic division of the grid into sub-grids can lead to unexpected behavior,
particularly in custom PDEs that were not designed for this use case.
As a rule of thumb, all local operations are fine (since they can be performed on
each subgrid), while global operations might need synchronization between all
subgrids. One example is integration, which has been implemented properly in py-pde.
Consequently, it is safe to use integral.